|
All other things being equal, an increase in Sample Size (n) reduces all types of Sampling Errors, including Alpha and Beta Errors and the Margin of Error. 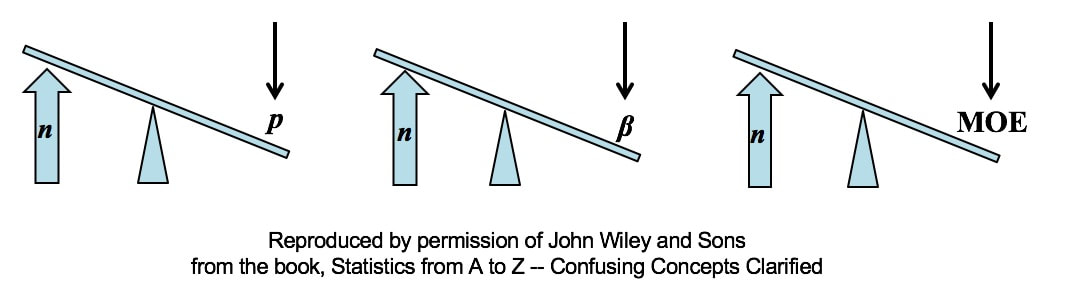 A Sampling "Error" is not a mistake. It is simply the reduction in accuracy to be expected when one makes an estimate based on a portion – a Sample – of the data in Population or Process. There are several types of Sampling Error.
Two types of Sampling Errors are described in terms of their Probabilities:
All three types of Sampling Error are reduced when the Sample Size is increased. This makes intuitive sense, because a very small Sample is more likely to not be a good representative of the properties of the larger Population or Process. But, the values of Statistics calculated from a much larger Sample are likely to be much closer to the values of the corresponding Population or Process Parameters For more on the statistical concepts mentioned here (p, β, MOE, Confidence Intervals, Statistical Errors, Samples and Sampling), please see my book or my YouTube channel -- both are titled Statistics from A to Z -- Confusing Concepts Clarified.
0 Comments
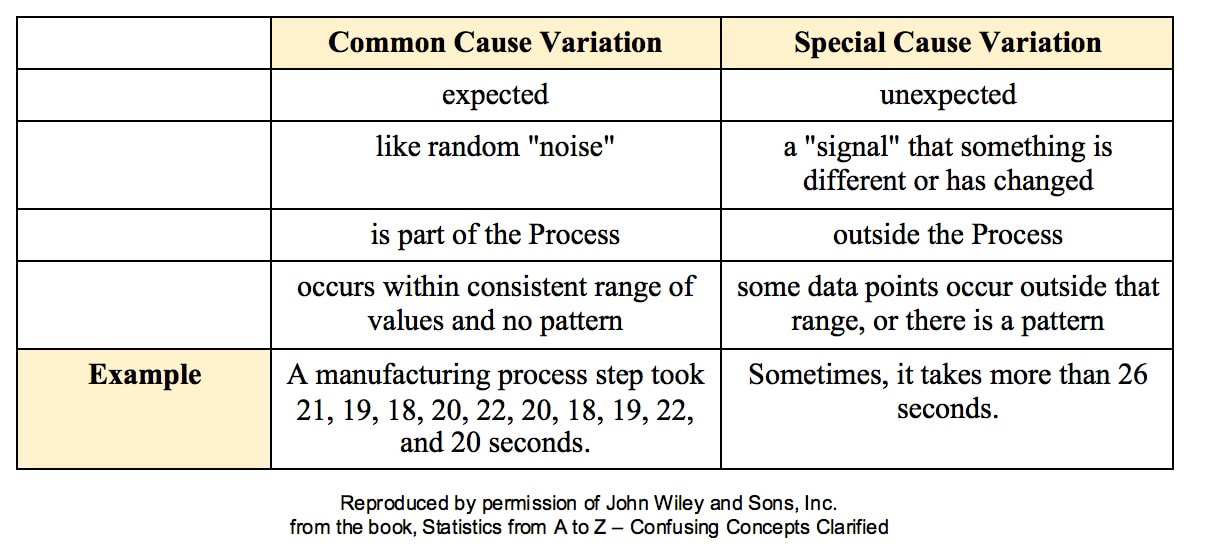 All processes have variation. A process can be said to be "under control", "stable", or "predictable" if the variation is
Such Variation is called Common Cause Variation; it is like random "noise" within an under-control process. Variation which is not Common Cause is called Special Cause Variation. It is a signal that factors outside the process are affecting it. Any Special Cause Variation must be eliminated before one can attempt to narrow the range of Common Cause Variation. Until we eliminate Special Cause Variation, we don't have a process that we can improve. There are factors outside the process which affect it, and that changes the actual process that is happening in ways that we don't know. Once we know that we have Special Cause Variation, we can use various Root Cause Analysis methods to identify the Special Cause, so that we can eliminate it. Only then can we use process/ quality improvement methods like Lean Six Sigma to try to reduce the Common Cause Variation. Here are some examples of Special Causes of Variation:
Here is an example of a Control Chart. Each point is the Mean of a small Sample of data. The Upper Control Limit (UCL) and the Lower Control Limit (LCL) are usually set at 3 Standard Deviations from the Center Line. 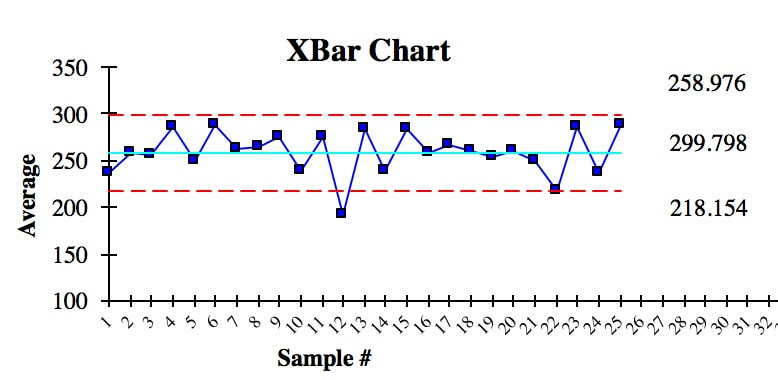 We see that there is one anomalous Sample Mean outside the Control Limits. This is due to Special Cause Variation. So, we need to do some root cause analysis to determine what caused that. And we need to make changes to eliminate it, before we can try to narrow the range of the Control Limits.
In addition to being within Control Chart limits, the data must be random. There are a number of Run Rules which describe patterns which are not random. Some patterns are not always easy to spot by eyeballing charts. Fortunately, the same software which produces Control Charts will usually also identify patterns described by the Run Rules. Here are some common patterns which indicate non-random (Special Cause) Variation. A Sigma is a Standard Deviation.
Reproduced by permission of John Wiley and Sons, Inc. from the book, Statistics from A to Z – Confusing Concepts Clarified |
AuthorAndrew A. (Andy) Jawlik is the author of the book, Statistics from A to Z -- Confusing Concepts Clarified, published by Wiley. Archives
March 2021
Categories |

 RSS Feed
RSS Feed