|
Variation is also known as "Variability", "Dispersion", "Spread", and "Scatter". (5 names for one thing is one more example why statistics is confusing.) Variation is 1 of 3 major categories of measures describing a Distribution or data set. The others are Center (aka "Central Tendency") with measures like Mean, Mode, and Median and Shape (with measures like Skew and Kurtosis). Variation measures how "spread out" the data is.  There are a number of different measures of Variation. This compare-and-contrast table shows the relative merits of each. 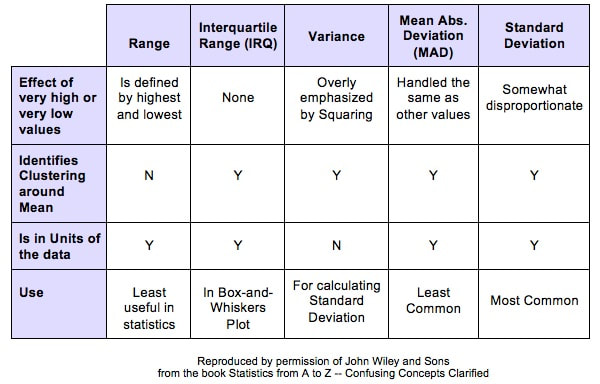
0 Comments
Leave a Reply. |
AuthorAndrew A. (Andy) Jawlik is the author of the book, Statistics from A to Z -- Confusing Concepts Clarified, published by Wiley. Archives
March 2021
Categories |

 RSS Feed
RSS Feed